Well, events 1030 and 1058 are very generic errors and can be caused by one of many different reasons. I often see questions at Experts Exchange on how to overcome these events. I don't have all the answers, but have helped out a lot of people diagnose and fix these events.
Explore Experts Exchange Articles
Our articles are written by a community of IT professionals and experts to provide insight on trending topics and common technology roadblocks.
Get AccessFeatured Article

Diagnosing and repairing Events 1030 and 1058
Get Access
Access our full library of articles written by our technology community. Read how-to guides, new perspectives on trending tech, and exclusive insights on industry news.
Articles For You
-
![Roles and Responsibilities in BCP]() Roles and Responsibilities in BCPThe enterprise recognizes that different employees and committees play a role in preparing the organization for the management of a crisis and the actual management of a crisis. This Article aims to define the Roles and Responsibilities of employees and senior managers involved in BCP.
Roles and Responsibilities in BCPThe enterprise recognizes that different employees and committees play a role in preparing the organization for the management of a crisis and the actual management of a crisis. This Article aims to define the Roles and Responsibilities of employees and senior managers involved in BCP. -
![About Streaming Services and Save with Tech]() About Streaming Services and Saving with TechA look and review of some of the most popular streaming services available today, along with a pointer to an app which could save you money based on my personal experiences. Enjoy.
About Streaming Services and Saving with TechA look and review of some of the most popular streaming services available today, along with a pointer to an app which could save you money based on my personal experiences. Enjoy. -
![Kofax PaperPort Professional]() Free in-place upgrade of Nuance PaperPort Professional 14.5 to Kofax PaperPort Professional 14.7Earlier this year, Kofax acquired Nuance's Document Imaging Division, which included PaperPort. Kofax recently released the first version of PaperPort under its stewardship — V14.7. This article explains Kofax's method for upgrading from PaperPort Professional 14.5 to Professional 14.7 at no cost.
Free in-place upgrade of Nuance PaperPort Professional 14.5 to Kofax PaperPort Professional 14.7Earlier this year, Kofax acquired Nuance's Document Imaging Division, which included PaperPort. Kofax recently released the first version of PaperPort under its stewardship — V14.7. This article explains Kofax's method for upgrading from PaperPort Professional 14.5 to Professional 14.7 at no cost. -
![]() Best Social Media Weapons To Skyrocket Your Marketing EffortsThe efficacy of social media has turned it into a powerful weapon, especially for businesses to promote their brands. Social media marketing is gaining a lot of traction and companies of all sizes are using it to reach prospects and customers.
Best Social Media Weapons To Skyrocket Your Marketing EffortsThe efficacy of social media has turned it into a powerful weapon, especially for businesses to promote their brands. Social media marketing is gaining a lot of traction and companies of all sizes are using it to reach prospects and customers. -
![outlook 2007]() Easy Methods to Remove Duplicate Emails in Outlook!Finding original email is quite difficult due to their duplicates. From this article, you will come to know why multiple duplicates of same emails appear and how to delete duplicate emails from Outlook securely and instantly while vital emails remain intact.
Easy Methods to Remove Duplicate Emails in Outlook!Finding original email is quite difficult due to their duplicates. From this article, you will come to know why multiple duplicates of same emails appear and how to delete duplicate emails from Outlook securely and instantly while vital emails remain intact. -
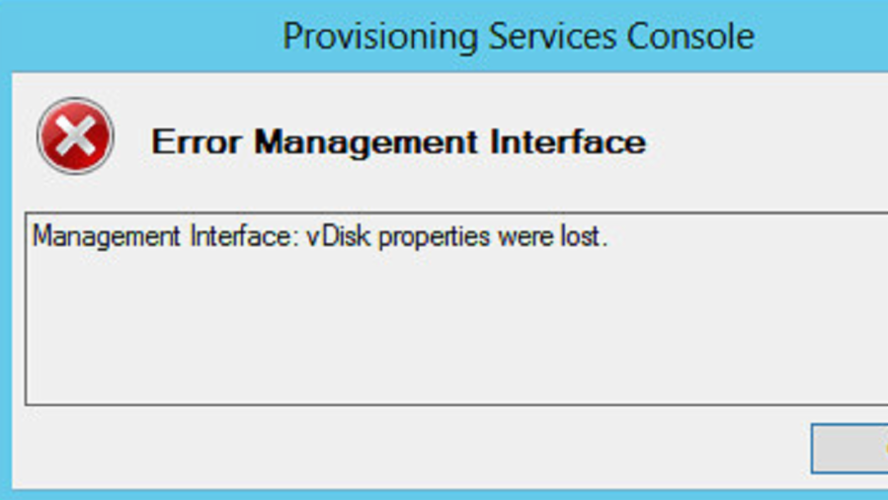
![]() Citrix Provisioning Services 7.X Error: Management Interface: vDisk properties were lostIf your vDisk VHD file gets deleted from the image store accidentally or on purpose, you won't be able to remove the vDisk from the PVS console. There is a known workaround that is solid.
Citrix Provisioning Services 7.X Error: Management Interface: vDisk properties were lostIf your vDisk VHD file gets deleted from the image store accidentally or on purpose, you won't be able to remove the vDisk from the PVS console. There is a known workaround that is solid. -
![I answered my own question with help. How do I close the question?]() I answered my own question with help. How do I close the question?If you answered your own question but had help from the experts, you can accept your answer as the solution and award points to the experts. Follow these steps (screen shots below):
I answered my own question with help. How do I close the question?If you answered your own question but had help from the experts, you can accept your answer as the solution and award points to the experts. Follow these steps (screen shots below): -
![]() Citrix XenDesktop 7.6 Citrix Policies Disable PeripheralsCitrix XenDesktop 7.6 Citrix Policies Disable Peripherals
Citrix XenDesktop 7.6 Citrix Policies Disable PeripheralsCitrix XenDesktop 7.6 Citrix Policies Disable Peripherals






Newest Articles
-
![]() Improve Network Security – Separate DNS from Active DirectoryWhile deploying Active Directory with integrated DNS makes managing a domain easier, it does come with security risks. Separating out DNS can actually improve security and make things harder for a threat actor.
Improve Network Security – Separate DNS from Active DirectoryWhile deploying Active Directory with integrated DNS makes managing a domain easier, it does come with security risks. Separating out DNS can actually improve security and make things harder for a threat actor. -
![]() Stopping Backdoor Spam On Microsoft M365As organizations move from an on premises Exchange environment SaaS based M365. There are configurations that may allow email to slip in passed typical email filtering systems. This is all based on the configuration and described in this article, along with the solution.
Stopping Backdoor Spam On Microsoft M365As organizations move from an on premises Exchange environment SaaS based M365. There are configurations that may allow email to slip in passed typical email filtering systems. This is all based on the configuration and described in this article, along with the solution. -
![]() Lessons Learned: Adding Used NVME Drive to HP ProLiant Server with ESXiInstalling used hardware in a home lab or other systems can have some challenges. Hopefully, the lesson learned here with a used NVMe drive will save someone else time and headache.
Lessons Learned: Adding Used NVME Drive to HP ProLiant Server with ESXiInstalling used hardware in a home lab or other systems can have some challenges. Hopefully, the lesson learned here with a used NVMe drive will save someone else time and headache. -
![Exchange & Powershell is a Long History]() Exchange & Powershell is a Long HistoryA long time ago, Experts-Exchange asked me to write a little article about some Exchange interesting Powershell commands. But I was never able to finish it properly. Here is the result of this work. Exchange has been the first Microsoft product that really needed Powershell to work!
Exchange & Powershell is a Long HistoryA long time ago, Experts-Exchange asked me to write a little article about some Exchange interesting Powershell commands. But I was never able to finish it properly. Here is the result of this work. Exchange has been the first Microsoft product that really needed Powershell to work!




Featured Author


Armed with my expertise and open to new insights, I stride forward with confidence and humility
-
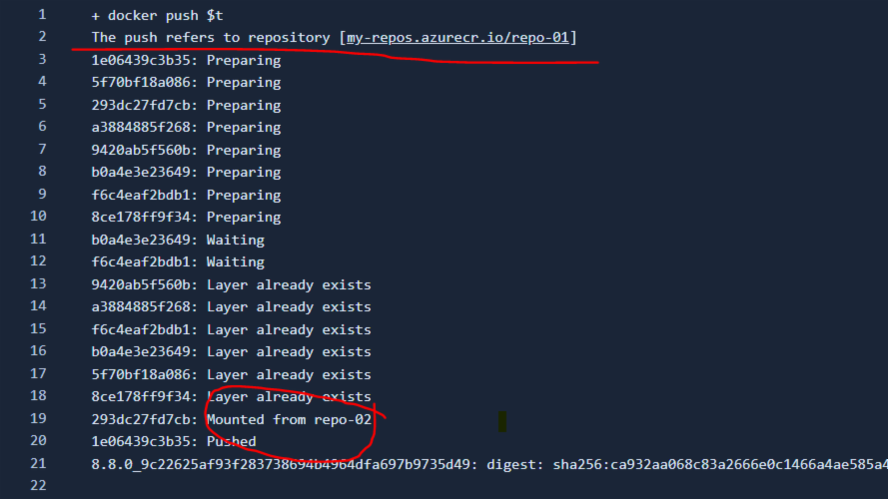
![]() Demystifying Docker: Understanding 'Mounted from' in Push LogsDocker's 'Mounted from' message unveils a sophisticated layer-sharing mechanism, strategically reusing layers across repositories for efficient storage use and accelerated image operations
Demystifying Docker: Understanding 'Mounted from' in Push LogsDocker's 'Mounted from' message unveils a sophisticated layer-sharing mechanism, strategically reusing layers across repositories for efficient storage use and accelerated image operations -
![Data Codes through Eyeglasses]() The Power of Closures in JavaScript: Understanding and Utilizing the ConceptClosures in JavaScript are powerful, allowing for state retention, currying and data persistence. This article offers a comprehensive guide to master closures, a fundamental concept for JavaScript development. Learn how to write more efficient and maintainable code using closures
The Power of Closures in JavaScript: Understanding and Utilizing the ConceptClosures in JavaScript are powerful, allowing for state retention, currying and data persistence. This article offers a comprehensive guide to master closures, a fundamental concept for JavaScript development. Learn how to write more efficient and maintainable code using closures

Popular Articles
-
![WARNING: 5 Reasons why you should NEVER fix a computer for free.]() WARNING: 5 Reasons why you should NEVER fix a computer for free.It is in our nature to love the puzzle. We are obsessed. The lot of us. We love puzzles. We love the…
WARNING: 5 Reasons why you should NEVER fix a computer for free.It is in our nature to love the puzzle. We are obsessed. The lot of us. We love puzzles. We love the… -
![How Do I Know What to Charge as an IT Consultant?]() How Do I Know What to Charge as an IT Consultant?[This article first appeared as "Why are IT services so expensive?" in my first attempt at a blog. …
How Do I Know What to Charge as an IT Consultant?[This article first appeared as "Why are IT services so expensive?" in my first attempt at a blog. … -
![Why you shouldn't use PST files]() Why you shouldn't use PST filesThey have been around for years and for thousands of Microsoft Outlook users and email …
Why you shouldn't use PST filesThey have been around for years and for thousands of Microsoft Outlook users and email … -
![Migrate Small Business Server 2003 to Exchange 2010 and Windows 2008 R2]() Migrate Small Business Server 2003 to Exchange 2010 and Windows 2008 R2This guide is intended to provide step by step instructions on how to migrate from Small Business …
Migrate Small Business Server 2003 to Exchange 2010 and Windows 2008 R2This guide is intended to provide step by step instructions on how to migrate from Small Business … -
![Outlook continually prompting for username and password]() Outlook continually prompting for username and passwordThere have been a lot of questions recently regarding Outlook prompting for a username and password …
Outlook continually prompting for username and passwordThere have been a lot of questions recently regarding Outlook prompting for a username and password …
Join a collaborative community of technology professionals.