Well, events 1030 and 1058 are very generic errors and can be caused by one of many different reasons. I often see questions at Experts Exchange on how to overcome these events. I don't have all the answers, but have helped out a lot of people diagnose and fix these events.
Explore Experts Exchange Articles
Our articles are written by a community of IT professionals and experts to provide insight on trending topics and common technology roadblocks.
Get AccessFeatured Article

Diagnosing and repairing Events 1030 and 1058
Get Access
Access our full library of articles written by our technology community. Read how-to guides, new perspectives on trending tech, and exclusive insights on industry news.
Articles For You
-
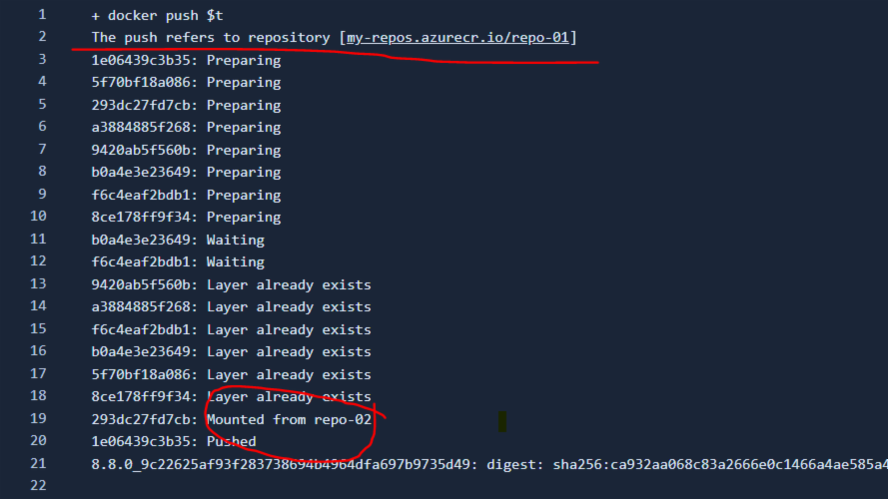
![]() Demystifying Docker: Understanding 'Mounted from' in Push LogsDocker's 'Mounted from' message unveils a sophisticated layer-sharing mechanism, strategically reusing layers across repositories for efficient storage use and accelerated image operations
Demystifying Docker: Understanding 'Mounted from' in Push LogsDocker's 'Mounted from' message unveils a sophisticated layer-sharing mechanism, strategically reusing layers across repositories for efficient storage use and accelerated image operations -
![]() Another Conditional Formatting Trick In ExcelHave you ever wanted to make your MS Excel spreadsheet more easy to follow? Here is one way to do just that.
Another Conditional Formatting Trick In ExcelHave you ever wanted to make your MS Excel spreadsheet more easy to follow? Here is one way to do just that. -
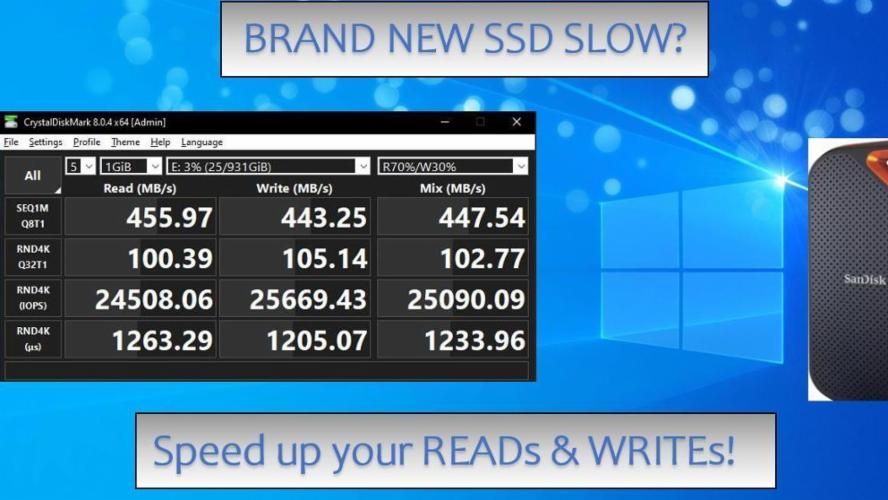
![]() The nuances of new age SSDs - Slow performance & SolutionPost purchasing a portable SSD recently, I ran into several performance issues. Namely, the new SSD (SanDisk Xtreme Pro 1TB) having slow speeds on data copy and the files (on disk) taking a lot of disk space. These issues are now sorted but I want to share this for anyone in the same boat.
The nuances of new age SSDs - Slow performance & SolutionPost purchasing a portable SSD recently, I ran into several performance issues. Namely, the new SSD (SanDisk Xtreme Pro 1TB) having slow speeds on data copy and the files (on disk) taking a lot of disk space. These issues are now sorted but I want to share this for anyone in the same boat. -
![Veeam immutable repository]() Part 4 - Build an immutable backup repository for Veeam Backup & Replication.For Veeam Backup & Replication, this guide will show you, step by step, how to create and implement a disk-based immutable backup repository from scratch. In this part: Create the immutable Veeam backup repository
Part 4 - Build an immutable backup repository for Veeam Backup & Replication.For Veeam Backup & Replication, this guide will show you, step by step, how to create and implement a disk-based immutable backup repository from scratch. In this part: Create the immutable Veeam backup repository -
![Veeam immutable repository]() Part 3 - Build an immutable backup repository for Veeam Backup & Replication.For Veeam Backup & Replication, this guide will show you, step by step, how to create and implement a disk-based immutable backup repository from scratch. In this part: Prepare the Linux server for Veeam.
Part 3 - Build an immutable backup repository for Veeam Backup & Replication.For Veeam Backup & Replication, this guide will show you, step by step, how to create and implement a disk-based immutable backup repository from scratch. In this part: Prepare the Linux server for Veeam. -
![Veeam immutable repository]() Part 1 - Build an immutable backup repository for Veeam Backup & Replication.For Veeam Backup & Replication, this guide will show you, step by step, how to create and implement a disk-based immutable backup repository from scratch. In this part: Prepare the install of Linux.
Part 1 - Build an immutable backup repository for Veeam Backup & Replication.For Veeam Backup & Replication, this guide will show you, step by step, how to create and implement a disk-based immutable backup repository from scratch. In this part: Prepare the install of Linux. -
![]() Feeling the Talent Shortage? 5 Ways to Build Your Tech TeamAs an IT professional, you know how hard IT teams work. How a team operates as a unit can make or break a project. Building a fundamentally cohesive tech team can make all the difference for any organization.
Feeling the Talent Shortage? 5 Ways to Build Your Tech TeamAs an IT professional, you know how hard IT teams work. How a team operates as a unit can make or break a project. Building a fundamentally cohesive tech team can make all the difference for any organization. -
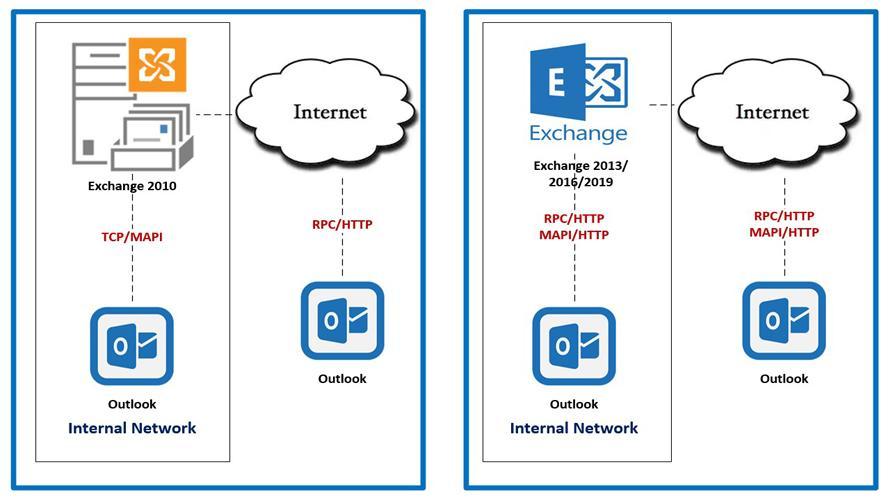
![]() Enable or disable Outlook Anywhere (RPC-HTTP/MAPI-HTTP) in Exchange Server.This article will help to do the below tasks. 1. Disable Outlook Anywhere for single mailbox. 2. Disable Outlook Anywhere for all mailboxes in the organization. 3. Enable Outlook Anywhere for single mailbox. 4. Enable Outlook Anywhere for all mailboxes in the organization.
Enable or disable Outlook Anywhere (RPC-HTTP/MAPI-HTTP) in Exchange Server.This article will help to do the below tasks. 1. Disable Outlook Anywhere for single mailbox. 2. Disable Outlook Anywhere for all mailboxes in the organization. 3. Enable Outlook Anywhere for single mailbox. 4. Enable Outlook Anywhere for all mailboxes in the organization.



Newest Articles
-
![]() Improve Network Security – Separate DNS from Active DirectoryWhile deploying Active Directory with integrated DNS makes managing a domain easier, it does come with security risks. Separating out DNS can actually improve security and make things harder for a threat actor.
Improve Network Security – Separate DNS from Active DirectoryWhile deploying Active Directory with integrated DNS makes managing a domain easier, it does come with security risks. Separating out DNS can actually improve security and make things harder for a threat actor. -
![]() Stopping Backdoor Spam On Microsoft M365As organizations move from an on premises Exchange environment SaaS based M365. There are configurations that may allow email to slip in passed typical email filtering systems. This is all based on the configuration and described in this article, along with the solution.
Stopping Backdoor Spam On Microsoft M365As organizations move from an on premises Exchange environment SaaS based M365. There are configurations that may allow email to slip in passed typical email filtering systems. This is all based on the configuration and described in this article, along with the solution. -
![]() Lessons Learned: Adding Used NVME Drive to HP ProLiant Server with ESXiInstalling used hardware in a home lab or other systems can have some challenges. Hopefully, the lesson learned here with a used NVMe drive will save someone else time and headache.
Lessons Learned: Adding Used NVME Drive to HP ProLiant Server with ESXiInstalling used hardware in a home lab or other systems can have some challenges. Hopefully, the lesson learned here with a used NVMe drive will save someone else time and headache. -
![Exchange & Powershell is a Long History]() Exchange & Powershell is a Long HistoryA long time ago, Experts-Exchange asked me to write a little article about some Exchange interesting Powershell commands. But I was never able to finish it properly. Here is the result of this work. Exchange has been the first Microsoft product that really needed Powershell to work!
Exchange & Powershell is a Long HistoryA long time ago, Experts-Exchange asked me to write a little article about some Exchange interesting Powershell commands. But I was never able to finish it properly. Here is the result of this work. Exchange has been the first Microsoft product that really needed Powershell to work!




Featured Author

Adam DiStefano, M.S, CEH, CISSP (Adam-DiStefanoMSCEHCISSP)

CERTIFIED EXPERT
Enterprise Cyber Security Leader | Ai Security Strategist & Advisor | Ai and Cybersecurity Researcher
-
![]() AI’s Crucial Role in Safeguarding Cryptography in the Era of Quantum ComputingIn the era of quantum computing, AI emerges as a powerful ally in fortifying cryptography. This article explores AI's crucial role in safeguarding data security, including post-quantum cryptography, quantum key distribution, error correction, protocol optimization, and network planning.
AI’s Crucial Role in Safeguarding Cryptography in the Era of Quantum ComputingIn the era of quantum computing, AI emerges as a powerful ally in fortifying cryptography. This article explores AI's crucial role in safeguarding data security, including post-quantum cryptography, quantum key distribution, error correction, protocol optimization, and network planning. -
![]() Ensuring the Security of Large Language Models: Strategies and Best PracticesExplore the essentials of securing Large Language Models (LLMs) in our comprehensive guide. Uncover the challenges of AI cybersecurity, learn to identify vulnerabilities, prevent adversarial attacks, and implement robust data protection. Stay ahead of the curve in maintaining model confidentiality .
Ensuring the Security of Large Language Models: Strategies and Best PracticesExplore the essentials of securing Large Language Models (LLMs) in our comprehensive guide. Uncover the challenges of AI cybersecurity, learn to identify vulnerabilities, prevent adversarial attacks, and implement robust data protection. Stay ahead of the curve in maintaining model confidentiality .


Popular Articles
-
![WARNING: 5 Reasons why you should NEVER fix a computer for free.]() WARNING: 5 Reasons why you should NEVER fix a computer for free.It is in our nature to love the puzzle. We are obsessed. The lot of us. We love puzzles. We love the…
WARNING: 5 Reasons why you should NEVER fix a computer for free.It is in our nature to love the puzzle. We are obsessed. The lot of us. We love puzzles. We love the… -
![How Do I Know What to Charge as an IT Consultant?]() How Do I Know What to Charge as an IT Consultant?[This article first appeared as "Why are IT services so expensive?" in my first attempt at a blog. …
How Do I Know What to Charge as an IT Consultant?[This article first appeared as "Why are IT services so expensive?" in my first attempt at a blog. … -
![Why you shouldn't use PST files]() Why you shouldn't use PST filesThey have been around for years and for thousands of Microsoft Outlook users and email …
Why you shouldn't use PST filesThey have been around for years and for thousands of Microsoft Outlook users and email … -
![Migrate Small Business Server 2003 to Exchange 2010 and Windows 2008 R2]() Migrate Small Business Server 2003 to Exchange 2010 and Windows 2008 R2This guide is intended to provide step by step instructions on how to migrate from Small Business …
Migrate Small Business Server 2003 to Exchange 2010 and Windows 2008 R2This guide is intended to provide step by step instructions on how to migrate from Small Business … -
![Outlook continually prompting for username and password]() Outlook continually prompting for username and passwordThere have been a lot of questions recently regarding Outlook prompting for a username and password …
Outlook continually prompting for username and passwordThere have been a lot of questions recently regarding Outlook prompting for a username and password …

Join a collaborative community of technology professionals.